The Challenge
Building a reliable data foundation for quantitative research requires solving two massive problems: Survivorship Bias and Lookahead Bias. Most retail datasets only include assets that exist today, ignoring failed projects. This leads to backtests that perform impossibly well because they never “bet” on the losers.
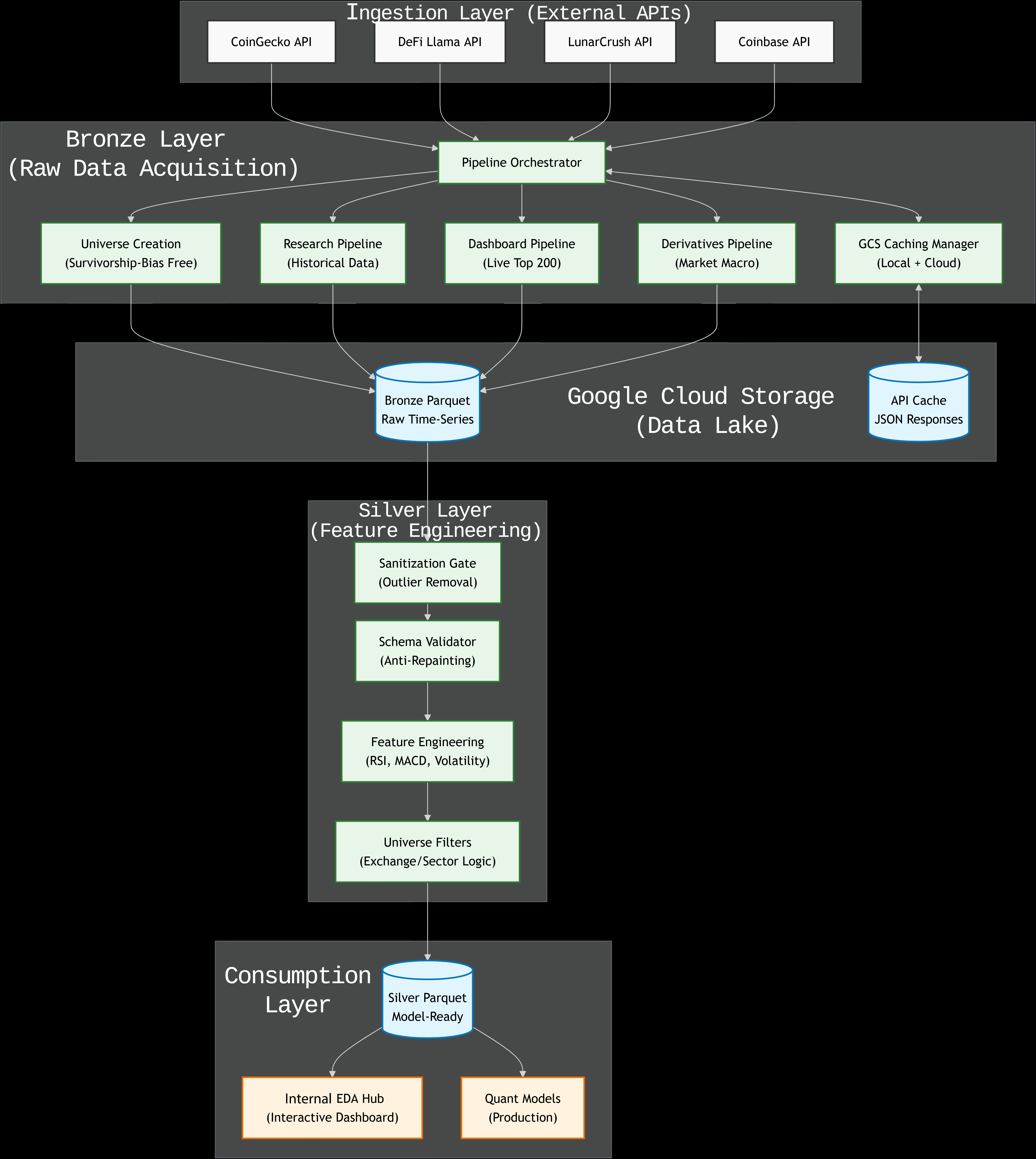
System Architecture
(Click the diagram to view full resolution)
The Solution
I architected a multi-stage ETL pipeline on Google Cloud Platform that reconstructs the Top 200 coin universe as it existed at any historical point in time.
Key Architectural Decisions
- Two-Tier Caching (GCSCachingManager):
- Level 1: Local disk cache for rapid development.
- Level 2: Shared Google Cloud Storage (GCS) bucket for team collaboration.
- Impact: Reduced external API calls by 90% and eliminated rate-limit bottlenecks.
- Bronze-to-Silver Layering:
- Bronze: Raw JSON responses from CoinGecko, DeFiLlama, and LunarCrush are stored immutably.
- Silver: A sanitization gate removes outliers and standardizes schemas before feature engineering occurs.
- Anti-Repainting Validation:
- A custom
SchemaValidatorruns on every pull request to ensure that historical data has not changed, protecting the integrity of our ML models.
- Point-in-Time Feature Engineering:
- Context: Raw data availability does not equal research readiness. To prevent lookahead bias, the pipeline implements strict lagging logic.
- Publication Lags: On-chain metrics (like TVL) and social sentiment scores are timestamped to their publication time, not their event time, preventing models from acting on information before it is public.
- Canonical Aggregation: The system automatically detects and merges liquidity from bridged assets (e.g., merging Wrapped Bitcoin volume into native Bitcoin) to create a unified view of asset liquidity without double-counting market capitalization.
- Containerized Orchestration:
- Reproducibility: The entire pipeline is containerized using Docker, ensuring that the execution environment—including Python 3.11 dependencies—is identical across local development and production.
- Logic: A fail-fast shell script enforces a strict dependency graph: Universe Generation → Ingestion → Validation → Transformation.
- Safety: If any step fails validation, the entire pipeline halts immediately, preventing corrupted data from silently propagating to downstream analytics dashboards.
The Result
This architecture moved the organization from ad-hoc CSV exports to a mature Data Lakehouse model.
- Reliability: The two-tier caching system reduced external API dependency by over 90%, virtually eliminating
429 Too Many Requestserrors during heavy backtesting sessions. - Accuracy: We successfully eliminated survivorship bias, resulting in backtests that accurately reflect historical market conditions rather than over-fitting to current winners.
- Scalability: The system now ingests millions of data points across market, on-chain, and social dimensions daily, serving as the single source of truth for both the internal analytics dashboard and the quantitative research team.